暂时没有归类。
凸包
一道模板题
首先凸包的定义:
用不严谨的话来讲,给定二维平面上的点集,凸包就是将最外层的点连接起来构成的凸多边形 ,它能包含点集中所有的点。
(百度百科给的解释)
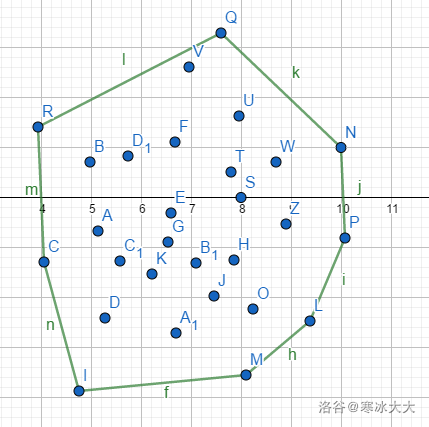
因此以下就可以算是一个凸包
求法有两个
求法 1
第一个是把凸包分为上下两部分,对于下半部分不难发现斜率是在递增的,因此考虑先给所有点按照从左到右从下到上排序,然后类似于单调栈维护一个斜率。
然后伪代码大概就长这样
1 2 3 4 5 for (i=1 ;i<=n;i++){ s[++size]=p[i]; while (size>=3 &&getk (s[size-2 ],s[size])<getk (s[size-2 ],s[size-1 ])) s[size-1 ]=s[size],size--; }
g e t k ( n o d e a , n o d e b ) getk(node~~a,node~~b) g e t k ( n o d e a , n o d e b )
对于上半部分凸包,只需要从右向左枚举即可。
求法2
上面的求法不需要高中数学功底因此可见只能解决较简单的问题 对于比较毒瘤的问题,这样进一步写下去就很麻烦,所以考虑求法2
就是Graham扫描法
首先前置芝士
1.极角排序
这里只介绍按照atan2的方法。
atan2(x,y) 即返回t a n α = x y tan \alpha =\frac{x}{y} t an α = y x α \alpha α α ∈ [ − π , π ] \alpha \in [-\pi,\pi] α ∈ [ − π , π ]
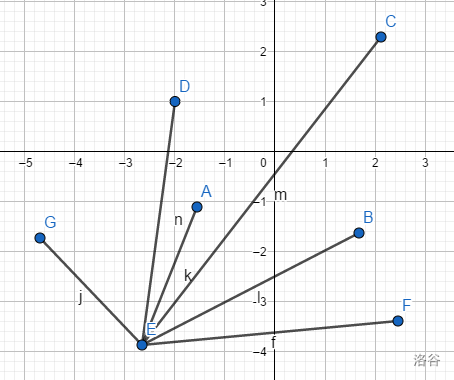
例如我们以左下角E(优先考虑最下)点对这些点极角排序,显然可见a
ABCDEFG的坐标:
7
排序的结果是这样的(FBCADG)可以理解为从0度逆时针扫一圈。
atan2 (x,y)当y=0时,t a n α tan\alpha t an α
2.叉积
如图所示p ⃗ 1 ∗ p ⃗ 2 \vec p_1 * \vec p_2 p 1 ∗ p 2
公式 p ⃗ 1 ∗ p ⃗ 2 = x 1 y 2 − x 2 y 1 \vec p_1 * \vec p_2 = x1y2-x2y1 p 1 ∗ p 2 = x 1 y 2 − x 2 y 1
原理可以参考下面这张出,出处大概在这里 ,由于图片加载太慢我放在图床上面了
同时四边形面积大于0说明p2在p1顺时针方向,如果==0重合,如果小于0就说明在逆时针方向
算叉积的时候可以用这个公式
( b x − a x ) ∗ ( c y − a y ) − ( b y − a y ) ∗ ( c x − a x ) (b_x-a_x)*(c_y-a_y)-(b_y-a_y)*(c_x-a_x) ( b x − a x ) ∗ ( c y − a y ) − ( b y − a y ) ∗ ( c x − a x )
= ( a x b y − b x a y ) + ( b x c y − c x b y ) + ( c x a y − a x c y ) =(a_xb_y-b_xa_y)+(b_xc_y-c_xb_y)+(c_xa_y-a_xc_y) = ( a x b y − b x a y ) + ( b x c y − c x b y ) + ( c x a y − a x c y )
= a ⃗ ∗ b ⃗ + b ⃗ ∗ c ⃗ + c ⃗ ∗ a ⃗ =\vec a*\vec b~+\vec b*\vec c ~+ \vec c*\vec a = a ∗ b + b ∗ c + c ∗ a
c如果在a右边的话,c ⃗ ∗ a ⃗ \vec c*\vec a c ∗ a
同理,如果上面的式子大于0,就说明c不在凸包里面。
如下图所示
刚开始d,b在栈里面,此时比较(d,c,b),发现>0则c入栈
同理对于d,比较(b,d,c)也大于0,入栈
运行完毕,发现O → b → c → d → O O\to b \to c \to d \to O O → b → c → d → O
对于小于O的情况的解释:
例如 b,c,N三个点,按照极角排序,就是b,c,N,现在我们假设b,c在栈里面,就要比较(b,N,c),此时小于0,即c并不在凸包上(N取代了他的位置)
实际上推完了上面的东西,你就能写出来代码了.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <map> #include <set> #include <algorithm> using namespace std;const double eps=1e-3 ;int n,m,size;double ans;struct node { double x,y; }p[200200 ],s[200200 ]; inline int cmp (node a,node b) double k1,k2; k1=atan2 ((a.y-p[1 ].y),(a.x-p[1 ].x)); k2=atan2 ((b.y-p[1 ].y),(b.x-p[1 ].x)); if (k1!=k2) return k1<k2; return a.x<b.x; } inline double getdis (node a,node b) return sqrt (1.0 *(a.x-b.x)*(a.x-b.x)+1.0 *(a.y-b.y)*(a.y-b.y)); } inline double getcj (node a,node b,node c) return 1ll *(b.x-a.x)*(c.y-a.y)-1ll *(b.y-a.y)*(c.x-a.x); } inline int bj (node a,node b) return (a.y>b.y||(a.y==b.y)&&(a.x>b.x)); } void gettb () p[0 ].x=p[0 ].y=0x3f3f3f3f ; register int i,j; for (i=1 ;i<=n;i++) { if (bj (p[0 ],p[i])) p[0 ]=p[i],j=i; } swap (p[j],p[1 ]); sort (p+2 ,p+n+1 ,cmp); s[++size]=p[1 ];s[++size]=p[2 ]; for (i=3 ;i<=n;) { if (size>=2 &&getcj (s[size-1 ],p[i],s[size])>=0 ) size--; else s[++size]=p[i++]; } s[0 ]=s[size]; for (i=1 ;i<=size;i++) ans+=getdis (s[i-1 ],s[i]); } int main () register int i,j; scanf ("%d" ,&n); for (i=1 ;i<=n;i++) scanf ("%lf %lf" ,&p[i].x,&p[i].y); gettb (); printf ("%.2lf" ,ans); return 0 ; }
旋转卡壳
旋(xuán)转(zhuàn)卡(qia)壳(qiào)
求凸包的直径一种方法
又是一道模板
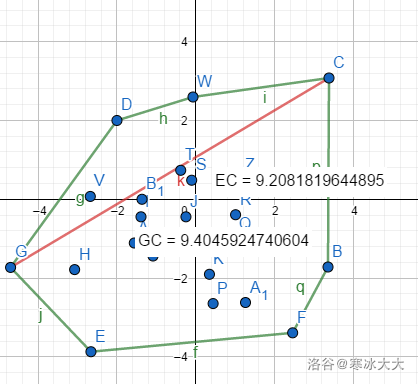
首先我们求出来一个凸包(绿色),然后才能找直径(红色)(bushi)
其实只要找到最长距离的两个点就可以了
找直径的方式:找两个点,做一条平行线,然后比较距离~~(其实并没有什么用,但是我们要引入旋转卡壳)~~
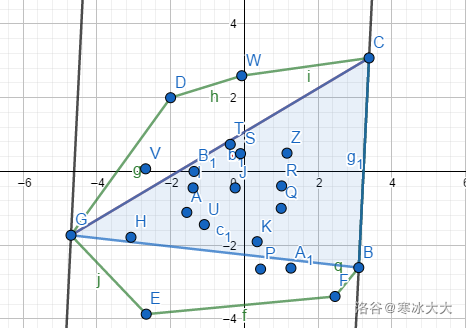
实际上我们可以转化为两个相邻的点的线段所在的直线到最远的点的距离,这样单纯的算距离就变成了求三角形面积。
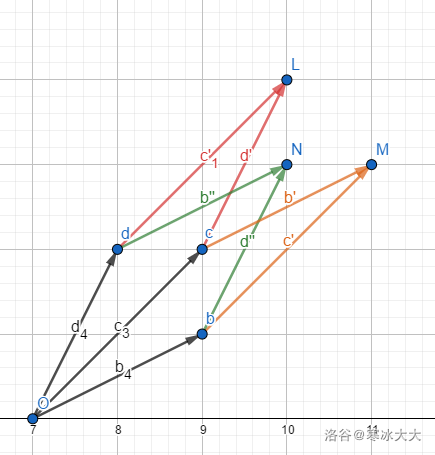
我们在做无用功?
不是,于是精彩的来了,(如下图)CB为底的三角形面积是单峰函数,我们扫描出来了CB为底的最大值,比较GC,GB的距离,然后逆时针上去(E → F → B → . . . E \to F \to B \to ... E → F → B → ...
这时候对底边面积最大的点一定在逆时针移动(用手推一推就好了)
这样不难发现三角形的顶点(这里姑且认为是临边不与这条平行线重合的点)不会再回到原来的点。
因此时间复杂度达到了美妙的O ( N l o g 2 N ) O(Nlog_2N) O ( Nl o g 2 N )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;struct node { int x,y; }p[200200 ],s[200200 ]; int n,size;inline int cmp (node a,node b) double k1,k2; k1=atan2 ((a.y-p[1 ].y),(a.x-p[1 ].x)); k2=atan2 ((b.y-p[1 ].y),(b.x-p[1 ].x)); if (k1==k2) return a.x<b.x; return k1<k2; } inline int getdis (node a,node b) return 1ll *(a.x-b.x)*(a.x-b.x)+1ll *(a.y-b.y)*(a.y-b.y); } inline int getcj (node a,node b,node c) return 1ll *(b.x-a.x)*(c.y-a.y)-1ll *(b.y-a.y)*(c.x-a.x); } inline int bj (node a,node b) return (a.y>b.y||(a.y==b.y)&&(a.x>b.x)); } inline void gettb () p[0 ].x=p[0 ].y=0x3f3f3f3f ; register int i,j; for (i=1 ;i<=n;i++) if (bj (p[0 ],p[i])) p[0 ]=p[i],j=i; swap (p[j],p[1 ]); sort (p+2 ,p+n+1 ,cmp); s[++size]=p[1 ]; s[++size]=p[2 ]; for (i=3 ;i<=n;) { if (size>=2 &&getcj (s[size-1 ],p[i],s[size])>=0 ) size--; else s[++size]=p[i++]; } s[0 ]=s[size]; } inline int getmmx () int ans=0 ; if (size==2 ) return getdis (s[0 ],s[1 ]); int j=2 ; for (int i=0 ;i<size;i++) { while (getcj (s[i],s[i+1 ],s[j])<getcj (s[i],s[i+1 ],s[j+1 ])) j=(j+1 )%size; ans=max (ans,max (getdis (s[i],s[j]),getdis (s[i+1 ],s[j]))); } return ans; } signed main () ios::sync_with_stdio (false ); register int i,j; cin>>n; for (i=1 ;i<=n;i++) { cin>>p[i].x>>p[i].y; } gettb (); cout<<getmmx ()<<endl; return 0 ; }
素数(质数)
O ( N ∗ N ) O(N*N) O ( N ∗ N ) 就是判断x x x [ 2 , x − 1 ] [2,x-1] [ 2 , x − 1 ]
O ( N ∗ N ) O(N*\sqrt N) O ( N ∗ N ) 由于约数成对出现,如果假如x=p1p2,那么p 1 ≤ ( x ) , p 2 ≥ ( x ) p1\leq\sqrt(x),p2\geq\sqrt(x) p 1 ≤ ( x ) , p 2 ≥ ( x )
证明不难。
O ( N ∗ l o g 2 l o g 2 N ) O(N*log_2log_2N) O ( N ∗ l o g 2 l o g 2 N )
很优秀,小学生应该都能想出来的算法。
1.找到1[]
2.找到[1,N]中3的倍数。
3.4被标记,跳过。
4.找到[1,N]中5的倍数。
……
1 2 3 4 5 6 for (i=2 ;i<=n;i++){ if (!f[i]) for (j=i+i;j<=n;j+=i) f[j]=1 ; }
主要代码就这么点。
O ( N ) O(N) O ( N ) 就是一个欧拉筛。
首先欧筛的大意就是用pri数组存素数,用v数组标记(也有用来存最小的
不难发现pri素组(存素数的) 保持单调上升(即2,3,5,…)。
1 2 3 4 5 6 7 8 9 10 11 12 13 inline void getprime () register int i,j; for (i=2 ;i<=maxn;i++) { if (!vis[i]) p[++cnt]=i; for (j=1 ;i*p[j]<=maxn&&j<=cnt;j++) { vis[i*p[j]]=1 ; if (i%p[j]==0 ) break ; } } }
i m o d p [ j ] i \mod p[j] i mod p [ j ] 0 0 0
GCD
欧几里得求GCD
即最大公约数
求法有很多种,但是一般用欧几里得
g c d ( a , b ) = g c d ( b , a % b ) gcd(a,b)=gcd(b,a\%b) g c d ( a , b ) = g c d ( b , a % b )
拓展欧几里得
当我们想要a x + b y = k ∗ g c d ( a , b ) , k ∈ Z , K ≠ 0 ax+by=k*gcd(a,b),k\in Z , K \neq 0 a x + b y = k ∗ g c d ( a , b ) , k ∈ Z , K = 0
假设我们现在求出了d = g c d ( a , b ) d=gcd(a,b) d = g c d ( a , b )
那么
a x + b y = g c d ( a , b ) a d x + b d y = 1 ax+by=gcd(a,b) \\
\frac{a}{d}x+\frac{b}{d}y=1
a x + b y = g c d ( a , b ) d a x + d b y = 1
显然这个时候d ∣ a , d ∣ b d|a,d|b d ∣ a , d ∣ b
a 0 x + b 0 y = 1 a 0 = q 1 b + r 1 b 0 = q 2 r 1 + r 2 r 1 = q 3 r 2 + r 3 a_0x+b_0y=1 \\
a_0=q_1b+r_1 \\
b_0=q_2r_1+r_2\\
r_1=q_3r_2+r_3\\
a 0 x + b 0 y = 1 a 0 = q 1 b + r 1 b 0 = q 2 r 1 + r 2 r 1 = q 3 r 2 + r 3
这时候根据gcd,我们可以求出更多的r r r
这个时候我们可以用gcd求出更多的r然后找到r1,最后就可以找到一组特解
( a 0 , b 0 ) (a_0,b_0) ( a 0 , b 0 )
那么很自然就会想出exgcd
a x + b y = g c d ( a , b ) = g c d ( b , a % b ) = b x + ( a % b ) y ax+by=gcd(a,b)=gcd(b,a\%b)=bx+(a\%b)y a x + b y = g c d ( a , b ) = g c d ( b , a % b ) = b x + ( a % b ) y
b x + ( a % b ) y = b x + ( a − ⌊ a b ⌋ ) y = a y + b x − b ⌊ a b ⌋ y = a y + b ( x − ⌊ a b ⌋ y ) bx+(a\%b)y=bx+(a-\lfloor\frac{a}{b}\rfloor)y=ay+bx-b\lfloor\frac{a}{b}\rfloor y\\=ay+b(x-\lfloor\frac{a}{b}\rfloor y) b x + ( a % b ) y = b x + ( a − ⌊ b a ⌋) y = a y + b x − b ⌊ b a ⌋ y = a y + b ( x − ⌊ b a ⌋ y )
但是我们首先要求到gcd才能接x,因此代码就要先注意一下
1 2 3 4 5 6 7 8 int exgcd (int a,int b,int &x,int &y) if (b==0 ) {x=1 ;y=0 ; return a;} int t=exgcd (b,a%b,x,y),tmp=x; x=y; y=tmp-(a/b)*y; return t; }
另一种求法
设
s = p 1 k 1 ∗ p 2 k 2 ∗ p 3 k 3 ∗ . . . p n k n t = p 1 k 1 ′ ∗ p 2 k 2 ′ ∗ p 3 k 3 ′ ∗ . . . p n k n ′ s={p_1}^{k_1}*{p_2}^{k_2}*{p_3}^{k_3}*...{p_n}^{k_n}\\
t={p_1}^{k'_1}*{p_2}^{k'_2}*{p_3}^{k'_3}*...{p_n}^{k'_n}
s = p 1 k 1 ∗ p 2 k 2 ∗ p 3 k 3 ∗ ... p n k n t = p 1 k 1 ′ ∗ p 2 k 2 ′ ∗ p 3 k 3 ′ ∗ ... p n k n ′
显然gcd为$
t = p 1 m i n ( k 1 , k 1 ′ ) ∗ p 2 m i n ( k 2 , k 2 ′ ) ∗ p 3 m i n ( k 3 , k 3 ′ ) ∗ . . . p n m i n ( k n , k n ′ ) t={p_1}^{min(k_1,k'_1)}*{p_2}^{min(k_2,k'_2)}*{p_3}^{min(k_3,k'_3)}*...{p_n}^{min(k_n,k'_n)}
t = p 1 min ( k 1 , k 1 ′ ) ∗ p 2 min ( k 2 , k 2 ′ ) ∗ p 3 min ( k 3 , k 3 ′ ) ∗ ... p n min ( k n , k n ′ )
有什么用?当出题人想考你有gcd ( a , x ) = c , l c m ( b , x ) = d \gcd(a,x)=c,lcm(b,x)=d g cd( a , x ) = c , l c m ( b , x ) = d
题目
大意,给定c 1 , c 2 , e 1 , e 2 , N c_1,c_2,e_1,e_2,N c 1 , c 2 , e 1 , e 2 , N m m m
c 1 , c 2 c_1,c_2 c 1 , c 2 N N N
{ c 1 ≡ m e 1 m o d N c 2 ≡ m e 2 m o d N \begin{cases}c_1 \equiv m^{e_1} ~mod~ N \\ c_2 \equiv m^{e_2}~mod~N\end{cases} { c 1 ≡ m e 1 m o d N c 2 ≡ m e 2 m o d N
我们现在合并成一个式子
c 1 ∗ c 2 ≡ m e 1 + e 2 m o d N c_1*c_2\equiv m^{e_1+e_2}~mod~N c 1 ∗ c 2 ≡ m e 1 + e 2 m o d N
好像并不能发现什么,来试试c 1 , c 2 c_1,c_2 c 1 , c 2
从互质这个地方出发
g c d ( c 1 , N ) = g c d ( c 2 , N ) = 1 gcd(c1,N)=gcd(c2,N)=1 g c d ( c 1 , N ) = g c d ( c 2 , N ) = 1
一想到互质,就可以来解x e 1 + y e 2 = 1 xe_1+ye_2=1 x e 1 + y e 2 = 1
那么就可以求出m了
但是x , y x,y x , y
c − x = ( c − 1 ) x c^{-x}=({c^{-1})}^x c − x = ( c − 1 ) x
所以我们只需要找到它的模N N N
另外还要注意到N很大,所以要不用龟速乘要不就用高精或者快速模
1 2 3 inline ll mul (ll x,ll y,ll p) return ((x*y-(ll)(((long double )x*y+0.5 )/p)*p)%p+p)%p; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;int x,y,n;int c1,c2,e1,e2;int exgcd (int a,int b,int &x,int &y) if (b==0 ) { x=1 ,y=0 ; return a; } int tmp=exgcd (b,a%b,x,y); int t=x; x=y; y=t-a/b*y; return tmp; } int gsc (int x,int y,int modp) int ans=0 ; while (y) { if (y&1 ) ans=(ans+x)%modp; x=(x+x)%modp; y>>=1 ; } return ans; } int ksm (int x,int y,int modp) int ans=1 ; while (y) { if (y&1 ) ans=gsc (x,ans,modp); x=gsc (x,x,modp); y>>=1 ; } return ans; } int inv (int x,int modp) int a,b; exgcd (x,modp,a,b); return (a+modp)%modp; } signed main () ios::sync_with_stdio (false ); register int i,j; int t; cin>>t; while (t--) { cin>>c1>>c2>>e1>>e2>>n; exgcd (e1,e2,x,y); if (x<0 ) x=-x,c1=inv (c1,n); if (y<0 ) y=-y,c2=inv (c2,n); cout<<gsc (ksm (c1,x,n),ksm (c2,y,n),n)<<endl; } }
逆元
当我们想要在除法意义下面取模的话
比如a b ( m o d p ) \frac{a}{b} \pmod p b a ( mod p )
我们不可能a % p b % p \frac{a\%p}{b\%p} b % p a % p
所以我们引入逆元
a a a a − 1 a^{-1} a − 1
并且a ∗ a − 1 ≡ 1 ( m o d p ) a*a^{-1}\equiv 1\pmod p a ∗ a − 1 ≡ 1 ( mod p )
为了好看,我们记a − 1 = x a^{-1}=x a − 1 = x
a x ≡ 1 ( m o d p ) ax\equiv 1 \pmod p a x ≡ 1 ( mod p )
诶,这个用e x g c d exgcd e xg c d
1 2 3 4 5 6 7 8 int exgcd (int a,int b,int &x,int &y) if (b==0 ) {x=1 ;y=0 ; return a;} int t=exgcd (b,a%b,x,y),tmp=x; x=y; y=tmp-(a/b)*y; return t; }
x x x
费马小定理
a ( p − 1 ) ≡ 1 ( m o d p ) , p a^{(p-1)}\equiv 1\pmod p,p a ( p − 1 ) ≡ 1 ( mod p ) , p
转化一下
a ∗ a p − 2 ≡ 1 ( m o d p ) a*a^{p-2}\equiv 1 \pmod p a ∗ a p − 2 ≡ 1 ( mod p )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;const int modp=19260817 ;int a,b;inline void qread (int &x) x=0 ; static char c=getchar (); while (!isdigit (c)) c=getchar (); while (isdigit (c)) {x=x*10 +c-'0' ; if (x>=modp) x%=modp; c=getchar ();} return ; } int ksm (int x,int y,int modp) int ans=1 ; while (y) { if (y&1 ) ans=(ans*x)%modp; x=(x*x)%modp; y>>=1 ; } return ans; } signed main () ios::sync_with_stdio (false ); qread (a); qread (b); if (b==0 ) { cout<<"Angry!" ; return 0 ; } cout<<(a*ksm (b,modp-2 ,modp))%modp<<endl; return 0 ; }
中国剩余定理
{ x ≡ 1 ( m o d 3 ) x ≡ 1 ( m o d 5 ) x ≡ 2 ( m o d 7 ) \begin{cases}x\equiv 1(mod~3)\\x\equiv 1(mod~5) \\x\equiv 2(mod~7)\end{cases} ⎩ ⎨ ⎧ x ≡ 1 ( m o d 3 ) x ≡ 1 ( m o d 5 ) x ≡ 2 ( m o d 7 )
这个时候先得到
{ x ≡ 1 ( m o d 3 ) x ≡ 1 ( m o d 5 ) x ≡ 1 ( m o d 7 ) \begin{cases}x \equiv 1(mod~3)\\x\equiv 1(mod~5) \\x\equiv 1(mod~7)\end{cases} ⎩ ⎨ ⎧ x ≡ 1 ( m o d 3 ) x ≡ 1 ( m o d 5 ) x ≡ 1 ( m o d 7 )
考虑特解
{ x ≡ 1 ( m o d 3 ) x ≡ 0 ( m o d 5 ) x ≡ 0 ( m o d 7 ) \begin{cases}x \equiv 1(mod~3)\\x\equiv 0(mod~5) \\x\equiv 0(mod~7)\end{cases} ⎩ ⎨ ⎧ x ≡ 1 ( m o d 3 ) x ≡ 0 ( m o d 5 ) x ≡ 0 ( m o d 7 )
此时显然可以表示为
令
s = 3 , t = 5 ∗ 7 s=3,t=5*7 s = 3 , t = 5 ∗ 7
M = 3 ∗ 5 ∗ 7 M=3*5*7 M = 3 ∗ 5 ∗ 7
x = 1 + s a , x = 0 + t b x=1+sa,x=0+tb x = 1 + s a , x = 0 + t b
1 + s a = t b , t b − s a = 1 1+sa=tb,tb-sa=1 1 + s a = t b , t b − s a = 1
显然也可以写成
t b + s a = 1 tb+sa=1 t b + s a = 1
那就可以通过解这个方程得到s,然后a n s + = s ∗ ( M / s ) ∗ 1 ans+=s*(M/s)*1 an s + = s ∗ ( M / s ) ∗ 1
然后记得给ans取模,并且上面这种解法对任意互质的p 1 , p 2 , p 3 . . . p n p_1,p_2,p_3...p_n p 1 , p 2 , p 3 ... p n
扩展中国剩余定理
当p不互质的时候,显然存在一组g c d ( a , b ) ≠ 1 gcd(a,b)\neq1 g c d ( a , b ) = 1
但是我们可以一直合并,让他最终变成一个同余方程,或者用对每组方程找到p作为lcm来处理,不过比上面难多了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;const int maxn=100100 ;int b[maxn],p[maxn];int n,m;int x,y;int exgcd (int a,int b,int &x,int &y) if (b==0 ) {x=1 ;y=0 ; return a;} int t=exgcd (b,a%b,x,y),tmp=x; x=y; y=tmp-(a/b)*y; return t; } inline int mul (int x,int y,int modp) int ans=0 ; while (y) { if (y&1 ) ans=(ans+x)%modp; x=(x+x)%modp; y>>=1 ; } return ans; } inline int excrt () int i,j; int ans=p[1 ]; int nowtot=b[1 ]; int lcm=1 ; for (i=2 ;i<=n;i++) { int tb,tp,tc; tb=nowtot; tp=b[i]; tc=(p[i]-ans%tp+tp)%tp; int gd=exgcd (tb,tp,x,y); tc/=gd; x=mul (x,tc,tp/gd); ans+=x*nowtot; nowtot*=(tp/gd); ans=((ans%nowtot)+nowtot)%nowtot; } return (ans%nowtot+nowtot)%nowtot; } signed main () ios::sync_with_stdio (false ); register int i,j; cin>>n; for (i=1 ;i<=n;i++) cin>>b[i]>>p[i]; cout<<excrt ()<<endl; }
矩阵
[ 1 2 4 5 7 8 ] \left[
\begin{array}{ccc}
1 & 2 \\
4 & 5 \\
7 & 8 \\
\end{array}
\right] 1 4 7 2 5 8
这就是个2 ∗ 3 2*3 2 ∗ 3
[ 1 2 3 4 5 6 ] \left[
\begin{array}{ccc}
1 & 2 &3 \\
4 & 5 &6\\
\end{array}
\right] [ 1 4 2 5 3 6 ]
这个是3*2的
这两东西相乘,得到一个2*2的矩阵
1 2 3 4 5 6 7 8 9 10 11 12 13 struct mat { int p[3 ][3 ]; mat (){ memset (p,0 ,sizeof (p));} void fst () { int i; for (i=1 ;i<=2 ;i++) p[i][i]=1 ; } }a,b;
知道了性质,就可以拓展一下,比如斐波那契数列
设有这么个矩阵
[ f [ n − 1 ] f [ n − 2 ] ] \left[
\begin{array}{ccc}
&f[n-1]&\\&f[n-2]&\\\end{array}
\right] [ f [ n − 1 ] f [ n − 2 ] ]
我们想把他变成
[ f [ n ] f [ n − 1 ] ] \left[
\begin{array}{ccc}
&f[n]&\\&f[n-1]&\\\end{array}
\right] [ f [ n ] f [ n − 1 ] ]
根据矩阵乘法的定义,显然
[ 1 1 1 0 ] \left[
\begin{array}{ccc}
1&1\\1&0\\\end{array}
\right] [ 1 1 1 0 ]
就满足
同时乘法满足交换律,意思就是我们吧这个矩阵k次方先求出来,然后再乘
[ f [ 2 ] f [ 1 ] ] \left[
\begin{array}{ccc}
f[2]\\f[1]\\\end{array}
\right] [ f [ 2 ] f [ 1 ] ]
(显然得到的答案并不是第n项,这地方你自己想办法处理)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;const int modp=1e9 +7 ;int n;struct mat { int p[3 ][3 ]; mat (){ memset (p,0 ,sizeof (p));} void fst () { int i; for (i=1 ;i<=2 ;i++) p[i][i]=1 ; } }a,b; mat operator *(mat a,mat b) { mat ans; int i,j,k; for (i=1 ;i<=2 ;i++) for (j=1 ;j<=2 ;j++) for (k=1 ;k<=2 ;k++) ans.p[i][j]=(a.p[i][k]*b.p[k][j]+ans.p[i][j])%modp; return ans; } mat ksm (int x) mat ans,tmp; ans.fst (); while (x) { if (x&1 ) ans=ans*a; a=a*a; x>>=1 ; } return ans; } signed main () ios::sync_with_stdio (false ); cin>>n; if (n<3 ) { cout<<1 <<endl; return 0 ;} a.p[1 ][1 ]=1 ; a.p[1 ][2 ]=1 ; a.p[2 ][1 ]=1 ; b.p[1 ][1 ]=b.p[1 ][2 ]=1 ; mat rans; rans=b*ksm (n-2 ); cout<<rans.p[1 ][1 ]; return 0 ; }
Lucas定理
对质数p p p
C n m ≡ C n % p m % p ∗ C n / p m / p ( m o d p ) C_n^m\equiv C_{n\%p}^{m\%p}*C_{n/p}^{m/p}(mod ~p) C n m ≡ C n % p m % p ∗ C n / p m / p ( m o d p )
但是为了方便递归理解,也有写成
L u c a s n m ≡ L u c a s n % p m % p ∗ C n / p m / p ( m o d p ) Lucas_n^m\equiv Lucas_{n\%p}^{m\%p}*C_{n/p}^{m/p}(mod ~p) Lu c a s n m ≡ Lu c a s n % p m % p ∗ C n / p m / p ( m o d p )
显然这是个简单到不能再简单的结论,所以我们考虑证明
设C a b C_a^b C a b p p p a , b a,b a , b
a = a 0 + a 1 p + a 2 p 2 + . . . . . + a n p n a=a_0+a_1p+a_2p^2+.....+a_np^n a = a 0 + a 1 p + a 2 p 2 + ..... + a n p n
b = b 0 + b 1 p + b 2 p 2 + . . . . . + b n p n b=b_0+b_1p+b_2p^2+.....+b_np^n b = b 0 + b 1 p + b 2 p 2 + ..... + b n p n
现在我们求一下( 1 + x ) p (1+x)^p ( 1 + x ) p
其实不用求,显而易见[ 1 , p − 1 ] [1,p-1] [ 1 , p − 1 ]
( 1 + x ) p ≡ 1 + x p ( m o d p ) (1+x)^p\equiv1+x^p (mod~p) ( 1 + x ) p ≡ 1 + x p ( m o d p )
这东西有啥用?
回头来看命题
C n m ≡ C n % p m % p ∗ C n / p m / p ( m o d p ) C_n^m\equiv C_{n\%p}^{m\%p}*C_{n/p}^{m/p}(mod ~p) C n m ≡ C n % p m % p ∗ C n / p m / p ( m o d p )
换成数学上的东西
C a b ≡ C a 0 b 0 ∗ C a 1 b 1 ∗ . . . ∗ C a n b n ( m o d p ) C_a^b \equiv C_{a_0}^{b_0}*C_{a_1}^{b_1}*...*C_{a_n}^{b_n}(mod ~p)
C a b ≡ C a 0 b 0 ∗ C a 1 b 1 ∗ ... ∗ C a n b n ( m o d p )
另外可以发现( 1 + x ) a (1+x)^a ( 1 + x ) a
( 1 + x ) a = ( 1 + x ) a 0 ∗ ( 1 + x ) a 1 p ∗ ( 1 + x ) a 2 p 2 ∗ . . . ∗ ( ( 1 + x ) a n p n ) ( 1 + x ) a ≡ ( 1 + x ) a 0 ∗ ( 1 + x p ) a 1 ∗ ( 1 + x p 2 ) a 2 ∗ . . . ∗ ( 1 + x p n ) a n ( m o d p ) (1+x)^a=(1+x)^{a_0}*(1+x)^{a_{1}p}*(1+x)^{a_{2} p_2}*...*((1+x)^{a_{n}p_n})\\
(1+x)^a\equiv(1+x)^{a_0}*(1+x^p)^{a_1}*(1+x^{p^2})^{a_2}*...*(1+x{p^n})^{a_n}(mod~p)
( 1 + x ) a = ( 1 + x ) a 0 ∗ ( 1 + x ) a 1 p ∗ ( 1 + x ) a 2 p 2 ∗ ... ∗ (( 1 + x ) a n p n ) ( 1 + x ) a ≡ ( 1 + x ) a 0 ∗ ( 1 + x p ) a 1 ∗ ( 1 + x p 2 ) a 2 ∗ ... ∗ ( 1 + x p n ) a n ( m o d p )
根据二项式定理,C a b C_a^b C a b x b x^b x b
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <cstdio> #include <cmath> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;int n,m,p;int a[200200 ];int qpow (int x, int y) int ans=1 ; x%=p; while (y) { if (y&1 ) ans=(ans*x)%p; x=(x*x)%p; y>>=1 ; } return ans; } int c (int x,int y) if (x<y) return 0 ; return ((a[x]*(qpow (a[y],p-2 ))%p)*qpow (a[x-y],p-2 ))%p; } int getlucas (int x,int y) if (y==0 ) return 1 ; return (c (x%p,y%p)*getlucas (x/p,y/p))%p; } signed main () int t; register int i,j; cin>>t; a[0 ]=1 ; while (t--) { cin>>n>>m>>p; for (i=1 ;i<=p;i++) a[i]=(a[i-1 ]*i)%p; cout<<getlucas (n+m,n)<<endl; } }
扩展卢卡斯
先给p分解质因数,然后用一个中国剩余定理的方程组合并即可。
但是m ! ( n − m ) ! m!(n-m)! m ! ( n − m )! p k p^k p k n ! n! n ! % p \%p % p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;int n,m,p;int x,y;int exgcd (int a,int b,int &x,int &y) if (b==0 ) {x=1 ; y=0 ;return a;} int tmp=exgcd (b,a%b,x,y),t=x; x=y; y=t-a/b*y; return tmp; } inline int getinv (int a,int p) exgcd (a,p,x,y); return ((x%p)+p)%p; } int ksm (int x,int y,int modp) int ans=1 ; while (y) { if (y&1 ) ans=(ans*x)%modp; x=(x*x)%modp; y>>=1 ; } return ans; } int f (int x,int pi,int pk) if (x==0 ) return 1 ; int p1=1 ; int i,j; for (i=1 ;i<=pk;i++) if (i%pi) p1*=i,p1%=pk; p1=ksm (p1,x/pk,pk); for (i=1 ;i<=x%pk;i++) if (i%pi) p1*=i,p1%=pk; return (f (x/pi,pi,pk)*p1)%pk; } int getk (int x,int p) int ans=0 ; while (x) ans+=x/p,x/=p; return ans; } inline int c (int n,int m,int pi,int pk) int ta,tb,tc; ta=f (n,pi,pk); tb=f (m,pi,pk); tc=f (n-m,pi,pk); int k=getk (n,pi); k-=getk (m,pi); k-=getk (n-m,pi); int ans=((ta*getinv (tb,pk))%pk)*getinv (tc,pk); ans=(ans%pk)*ksm (pi,k,pk); ans%=pk; return ans; } inline int crt (int a,int b) return getinv (p/b,b)%p*(p/b)%p*(a)%p; } inline int exlucas (int n,int m) int i,tmp=p; int ans=0 ,pk=1 ; int len=sqrt (p)+5 ; for (i=2 ;i<=len;i++) { if (tmp%i!=0 ) continue ; pk=1 ; while (tmp%i==0 ) pk*=i,tmp/=i; ans=(ans+crt (c (n,m,i,pk),pk))%p; } if (tmp!=1 ) ans=(ans+crt (c (n,m,tmp,tmp),tmp))%p; return ((ans%p)+p)%p; } signed main () ios::sync_with_stdio (false ); cin>>n>>m>>p; cout<<exlucas (n,m)<<endl; }
1.复数
BSGS
带步小步算法
给定一个质数 pp ,以及一个整数 bb ,一个整数 nn ,现在要求你计算一个最小的 l l l b l ≡ n ( m o d p ) b^l \equiv n \pmod p b l ≡ n ( mod p )
设l = k ∗ a − c l=k*a-c l = k ∗ a − c
b k ∗ a − c ≡ n ( m o d p ) b^{k*a-c}\equiv n \pmod p b k ∗ a − c ≡ n ( mod p )
b k ∗ a ≡ n ∗ b c ( m o d p ) b^{k*a}\equiv n*b^c \pmod p b k ∗ a ≡ n ∗ b c ( mod p )
现在我们需要枚举k和c,所以要找到一个最好的c c c
用分块思想想一想啊,显然a = p a=\sqrt{p} a = p
而且可以保证[ 0 , p − 1 ] [0,p-1] [ 0 , p − 1 ]
所以找符合条件的k ∗ p k*\sqrt{p} k ∗ p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;const int max=1001000 ;map < int , int > mp; int p,b,n,m; int qpow (int x,int y) int ans=1 ; while (y) { if (y&1 ) ans=(ans*x)%p; x=(x*x)%p; y>>=1 ; } return ans; } signed main () ios::sync_with_stdio (false ); register int i,j; cin>>p>>b>>n; int phi=p; m=ceil (sqrt (phi)); j=n; for (i=0 ;i<=m;i++) { mp[j]=i; j=(j*b)%p; } int jmp=qpow (b,m); j=jmp; for (i=1 ;i<=m;i++) { if (mp.count (j)) {cout<<i*m-mp[j]<<endl; return 0 ;} j=(j*jmp)%p; } cout<<"no solution" <<endl; return 0 ; }
欧拉定理
欧拉函数
ϕ ( x ) \phi(x) ϕ ( x ) φ ( x ) \varphi(x) φ ( x ) 1 → x 1\to x 1 → x x x x
显然ϕ ( p ) = p − 1 , p \phi(p)=p-1,p ϕ ( p ) = p − 1 , p
从这里我们可以推导出
ϕ ( p e ) = ( p − 1 ) ∗ p e − 1 \phi(p^e)=(p-1)*p^{e-1} ϕ ( p e ) = ( p − 1 ) ∗ p e − 1
根据唯一分解定理,有
P = k 1 e 1 ∗ p 2 e 2 ∗ . . . ∗ p n e n ϕ ( P ) = ϕ ( p 1 e 1 ) ∗ ϕ ( p 2 e 2 ) ∗ . . . ∗ ϕ ( p n e n ) = Π i = 1 n ( p i − 1 ) ∗ ( p i e i − 1 ) = Π i = 1 n ( 1 − 1 p i ) ∗ ( p i e i ) = n ∗ Π i = 1 n ( 1 − 1 p i ) \begin{align}
P&=k_1^{e_1}*p_2^{e_2}*...*p_n^{e_n}\\
\phi(P)&=\phi(p_1^{e_1})*\phi(p_2^{e_2})*...*\phi(p_n^{e_n})\\
&= \Pi_{i=1}^{n} (p_i-1)*(p_i^{e_i-1}) \\
&= \Pi_{i=1}^{n} (1-\frac{1}{p_i})*(p_i^{e_i}) \\
&= n*\Pi_{i=1}^{n} (1-\frac{1}{p_i})
\end{align}
P ϕ ( P ) = k 1 e 1 ∗ p 2 e 2 ∗ ... ∗ p n e n = ϕ ( p 1 e 1 ) ∗ ϕ ( p 2 e 2 ) ∗ ... ∗ ϕ ( p n e n ) = Π i = 1 n ( p i − 1 ) ∗ ( p i e i − 1 ) = Π i = 1 n ( 1 − p i 1 ) ∗ ( p i e i ) = n ∗ Π i = 1 n ( 1 − p i 1 )
我们就可以用这种方式求出ϕ ( n ) \phi(n) ϕ ( n )
1 2 3 4 5 6 7 8 9 10 void phi_table (int n) phi[1 ]=1 ; for (int i=2 ;i<=n;i++) if (!phi[i]) for (int j=i;j<=n;j+=i) { if (!phi[j])phi[j]=j; phi[j]=phi[j]/i*(i-1 ); } }
对于单个n,还有一个O ( N ) O(\sqrt{N}) O ( N )
1 2 3 4 5 6 7 8 9 10 signed main () ios::sync_with_stdio (false ); register int i; cin>>m; phi=m; for (i=2 ;i*i<=m;i++) if (tmp%i==0 ){phi-=phi/i; while (tmp%i==0 ) tmp/=i;} if (tmp!=1 ) phi-=phi/tmp; }
欧拉定理
a ϕ ( m ) ≡ 1 ( m o d m ) , a ⊥ m a^{\phi(m)}\equiv1 (~mod~m),a\perp m a ϕ ( m ) ≡ 1 ( m o d m ) , a ⊥ m
证明:证明这个数有ϕ \phi ϕ a p − 1 a^{p-1} a p − 1 p p p a a a
扩展欧拉定理
先咕一下证明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <iostream> #include <cmath> #include <cstdio> #include <cstring> #include <queue> #include <stack> #include <vector> #include <set> #include <map> #include <algorithm> #define int long long using namespace std;int a,b,m,phi,tmp,bj;inline void qread (int &x) x=0 ; static char c=getchar (); while (!isdigit (c)) c=getchar (); while (isdigit (c)) {x=x*10 +c-'0' ; if (x>=phi) x%=phi,bj=1 ; c=getchar ();} return ; } inline int ksm (int x,int y,int modp) int ans=1 ; while (y) { if (y&1 ) ans=(ans*x)%modp; x=(x*x)%modp; y>>=1 ; } return ans; } signed main () register int i,j; cin>>a>>m; phi=m; tmp=m; for (i=2 ;i*i<=m;i++) if (tmp%i==0 ){phi-=phi/i; while (tmp%i==0 ) tmp/=i;} if (tmp!=1 ) phi-=phi/tmp; qread (b); cout<<ksm (a,bj?b+phi:b,m); }